Recently we have been running into performance issues with load tests in one of our environments. When digging into the issue with Instana, we do not get much useful information. It just says that the time is spent in “Network”.
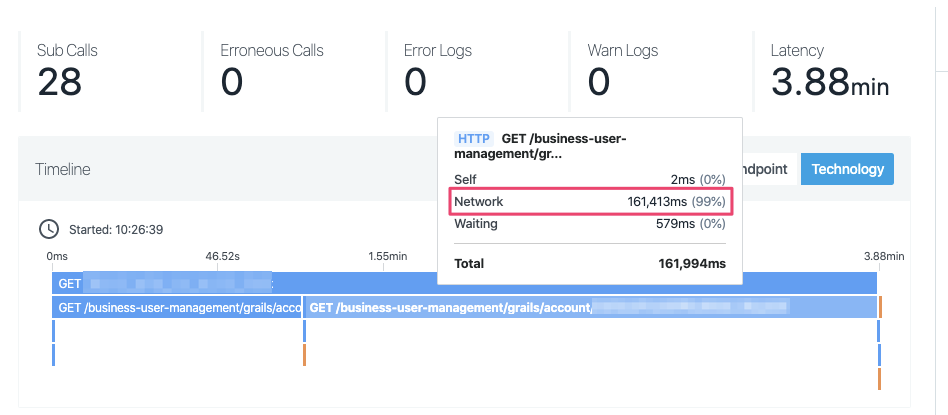
Instana calculates this network time by seeing when the trace “leaves” one instrumented system, and when it “enters” another instrumented system. However, Instana only really instruments the application layer. So there are still many layers that could be causing an issue.
Really the Network
The network could really be the culprit. Slow connections, bogged down switches or load balancers, etc. These could all keep a connection from reaching the destination within an acceptable time.
However, these should be caught with an appropriate “connect timeout” setting. Ours is appropriately low in this case; certainly not minutes. So that is unlikely the issue.
I am no expert on this, so maybe there are still scenarios where the network may still be the issue here. Perhaps in scenarios where the load balancer is holding onto connections with keep alives and all that there could still be a small connect time, but it isn’t really connected. This environment also contains Kubernetes, so maybe the iptables and other routing framework within Kubernetes itself is throwing things off.
The Underlying OS
On top of the network itself, we also have the underlying OS layer. This is actually dealing with the sockets and connections. Your application has some kind of worker queue that it uses to “buffer” requests. One could imagine a situation where this queue is full, so your application will not accept more work. But the OS doesn’t necessarily know that. It may be configured in a way that it will continue to accept some connections, and hold them in its own queue until your app is ready to accept new connections.
This is the type of scenario that I can see happening in our use case. I just do not yet know of a way to verify if this is the case. Perhaps radically reducing the size of the application’s worker queue would show this better? Maybe adjusting limit settings in the OS?
Circuit Breaker
In this scenario, no matter what the real cause is, it is quite clear that somebody is getting too much work. Some load shedding should be put in place. This would allow the system that is overloaded some time to catch back up. If it is a particular instance of the service that is behaving poorly, it should be removed and replaced.
These are all things you should do in a microservice world. That doesn’t mean they are always done…